信頼的-権威のあるDP-700日本語版受験参考書試験-試験の準備方法DP-700全真模擬試験
Wiki Article
P.S. JpshikenがGoogle Driveで共有している無料かつ新しいDP-700ダンプ:https://drive.google.com/open?id=1_U42If3OHWuLB628KI0cymEgkxvGUbwq
DP-700試験問題の継続的な刷新により、当社は大きな市場シェアを占めています。強力な研究センターを構築し、DP-700トレーニングガイドでより良い仕事をするために強力なチームを所有しています。Microsoftこれまで、DP-700学習教材に関する多くの特許を取得しています。一方で、当社は改修の恩恵を受けています。お客様は当社の製品を選択する可能性が高くなります。一方、私たちが投資したお金は有意義なものであり、DP-700試験の新しい学習スタイルを刷新するのに役立ちます。
Microsoft DP-700 認定試験の出題範囲:
| トピック | 出題範囲 |
|---|---|
| トピック 1 |
|
| トピック 2 |
|
| トピック 3 |
|
Microsoft DP-700全真模擬試験、DP-700試験参考書
DP-700の実際の試験をMicrosoft購入し、スコアを提供したお客様から得られたデータは、DP-700試験問題の高い合格率が98%〜100%であることを示しています。 これは、市場で見つけて比較するのが難しいです。 そして、Jpshiken優秀なクライアントからの数多くの熱烈なフィードバックは、DP-700の勉強の急流だけでなく、オンラインの誠実で役立つ24時間のカスタマーサービスにも高い評価を与えています。 これらはすべて、私たちがこのキャリアで最高のベンダーであり、DP-700試験の最初の試行で成功を収める権限があることをImplementing Data Engineering Solutions Using Microsoft Fabric証明しています。
Microsoft Implementing Data Engineering Solutions Using Microsoft Fabric 認定 DP-700 試験問題 (Q70-Q75):
質問 # 70
You need to schedule the population of the medallion layers to meet the technical requirements.
What should you do?
- A. Schedule multiple data pipelines.
- B. Schedule an Apache Spark job.
- C. Schedule a notebook.
- D. Schedule a data pipeline that calls other data pipelines.
正解:D
解説:
The technical requirements specify that:
Medallion layers must be fully populated sequentially (bronze → silver → gold). Each layer must be populated before the next.
If any step fails, the process must notify the data engineers.
Data imports should run simultaneously when possible.
Why Use a Data Pipeline That Calls Other Data Pipelines?
A data pipeline provides a modular and reusable approach to orchestrating the sequential population of medallion layers.
By calling other pipelines, each pipeline can focus on populating a specific layer (bronze, silver, or gold), simplifying development and maintenance.
A parent pipeline can handle:
- Sequential execution of child pipelines.
- Error handling to send email notifications upon failures.
- Parallel execution of tasks where possible (e.g., simultaneous imports into the bronze layer).
Topic 1, Contoso, Ltd
Overview
This is a case study. Case studies are not timed separately. You can use as much copyright time as you would like to complete each case. However, there may be additional case studies and sections on this copyright. You must manage your time to ensure that you are able to complete all questions included on this copyright in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the copyright. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview. Company Overview
Contoso, Ltd. is an online retail company that wants to modernize its analytics platform by moving to Fabric. The company plans to begin using Fabric for marketing analytics.
Overview. IT Structure
The company's IT department has a team of data analysts and a team of data engineers that use analytics systems.
The data engineers perform the ingestion, transformation, and loading of data. They prefer to use Python or SQL to transform the data.
The data analysts query data and create semantic models and reports. They are qualified to write queries in Power Query and T-SQL.
Existing Environment. Fabric
Contoso has an F64 capacity named Cap1. All Fabric users are allowed to create items.
Contoso has two workspaces named WorkspaceA and WorkspaceB that currently use Pro license mode.
Existing Environment. Source Systems
Contoso has a point of sale (POS) system named POS1 that uses an instance of SQL Server on Azure Virtual Machines in the same Microsoft Entra tenant as Fabric. The host virtual machine is on a private virtual network that has public access blocked. POS1 contains all the sales transactions that were processed on the company's website.
The company has a software as a service (SaaS) online marketing app named MAR1. MAR1 has seven entities. The entities contain data that relates to email open rates and interaction rates, as well as website interactions. The data can be exported from MAR1 by calling REST APIs. Each entity has a different endpoint.
Contoso has been using MAR1 for one year. Data from prior years is stored in Parquet files in an Amazon Simple Storage Service (Amazon S3) bucket. There are 12 files that range in size from 300 MB to 900 MB and relate to email interactions.
Existing Environment. Product Data
POS1 contains a product list and related data. The data comes from the following three tables:
Products
ProductCategories
ProductSubcategories
In the data, products are related to product subcategories, and subcategories are related to product categories.
Existing Environment. Azure
Contoso has a Microsoft Entra tenant that has the following mail-enabled security groups:
DataAnalysts: Contains the data analysts
DataEngineers: Contains the data engineers
Contoso has an Azure subscription.
The company has an existing Azure DevOps organization and creates a new project for repositories that relate to Fabric.
Existing Environment. User Problems
The VP of marketing at Contoso requires analysis on the effectiveness of different types of email content. It typically takes a week to manually compile and analyze the data. Contoso wants to reduce the time to less than one day by using Fabric.
The data engineering team has successfully exported data from MAR1. The team experiences transient connectivity errors, which causes the data exports to fail.
Requirements. Planned Changes
Contoso plans to create the following two lakehouses:
Lakehouse1: Will store both raw and cleansed data from the sources
Lakehouse2: Will serve data in a dimensional model to users for analytical queries Additional items will be added to facilitate data ingestion and transformation.
Contoso plans to use Azure Repos for source control in Fabric.
Requirements. Technical Requirements
The new lakehouses must follow a medallion architecture by using the following three layers: bronze, silver, and gold. There will be extensive data cleansing required to populate the MAR1 data in the silver layer, including deduplication, the handling of missing values, and the standardizing of capitalization.
Each layer must be fully populated before moving on to the next layer. If any step in populating the lakehouses fails, an email must be sent to the data engineers.
Data imports must run simultaneously, when possible.
The use of email data from the Amazon S3 bucket must meet the following requirements:
Minimize egress costs associated with cross-cloud data access.
Prevent saving a copy of the raw data in the lakehouses.
Items that relate to data ingestion must meet the following requirements:
The items must be source controlled alongside other workspace items.
Ingested data must land in the bronze layer of Lakehouse1 in the Delta format.
No changes other than changes to the file formats must be implemented before the data lands in the bronze layer.
Development effort must be minimized and a built-in connection must be used to import the source data.
In the event of a connectivity error, the ingestion processes must attempt the connection again.
Lakehouses, data pipelines, and notebooks must be stored in WorkspaceA. Semantic models, reports, and dataflows must be stored in WorkspaceB.
Once a week, old files that are no longer referenced by a Delta table log must be removed.
Requirements. Data Transformation
In the POS1 product data, ProductID values are unique. The product dimension in the gold layer must include only active products from product list. Active products are identified by an IsActive value of 1.
Some product categories and subcategories are NOT assigned to any product. They are NOT analytically relevant and must be omitted from the product dimension in the gold layer.
Requirements. Data Security
Security in Fabric must meet the following requirements:
The data engineers must have read and write access to all the lakehouses, including the underlying files.
The data analysts must only have read access to the Delta tables in the gold layer.
The data analysts must NOT have access to the data in the bronze and silver layers.
The data engineers must be able to commit changes to source control in WorkspaceA.
質問 # 71
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database. The table contains the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:
Does this meet the goal?
- A. no
- B. Yes
正解:A
解説:
This code does not meet the goal because it uses sort by without specifying the order, which defaults to ascending, but explicitly mentioning asc improves clarity.
Correct code should look like:
質問 # 72
You have a Fabric workspace that contains a warehouse named Warehouse1.
In Warehouse1, you create a table named DimCustomer by running the following statement.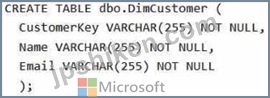
You need to set the Customerkey column as a primary key of the DimCustomer table.
Which three code segments should you run in sequence? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.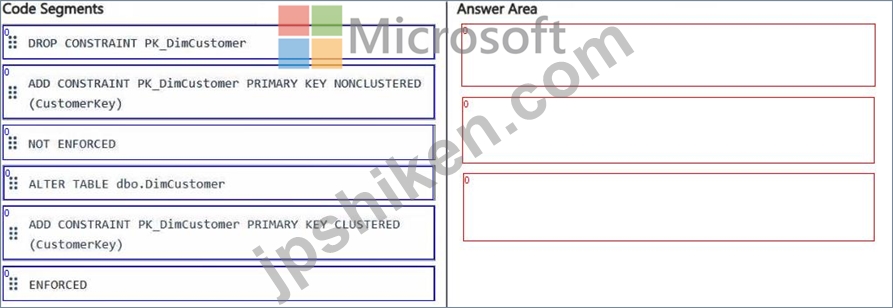
正解:
解説: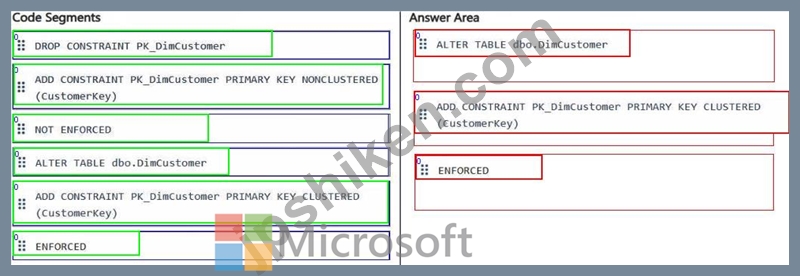
質問 # 73
HOTSPOT
You have a Fabric workspace named Workspace1_DEV that contains the following items:
10 reports
Four notebooks
Three lakehouses
Two data pipelines
Two Dataflow Gen1 dataflows
Three Dataflow Gen2 dataflows
Five semantic models that each has a scheduled refresh policy
You create a deployment pipeline named Pipeline1 to move items from Workspace1_DEV to a new workspace named Workspace1_TEST.
You deploy all the items from Workspace1_DEV to Workspace1_TEST.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
正解:
解説:
Explanation:
質問 # 74
You have a Fabric workspace named Workspace1 that contains an Apache Spark job definition named Job1.
You have an Azure SQL database named Source1 that has public internet access disabled.
You need to ensure that Job1 can access the data in Source1.
What should you create?
- A. a managed private endpoint
- B. an integration runtime
- C. a data management gateway
- D. an on-premises data gateway
正解:A
解説:
To allow Job1 in Workspace1 to access an Azure SQL database (Source1) with public internet access disabled, you need to create a managed private endpoint. A managed private endpoint is a secure, private connection that enables services like Fabric (or other Azure services) to access resources such as databases, storage accounts, or other services within a virtual network (VNet) without requiring public internet access.
This approach maintains the security and integrity of your data while enabling access to the Azure SQL database.
質問 # 75
......
トレントのDP-700ガイドは、これらすべての質問を解決してDP-700試験に合格するのに役立ちます。 弊社JpshikenのDP-700学習資料は、暦年の試験概要と業界動向に従って、長年にわたって多くの専門家によって簡素化され、まとめられています。 したがって、DP-700学習教材は理解しやすく、把握しやすいです。 人生には、自分の業界を変えたい人もたくさんいます。 彼らはしばしば、業界に参入するための足がかりとして専門的なDP-700資格試験を受けます。 あなたがこれらの人々の1人である場合、MicrosoftのDP-700試験エンジンが最良の選択となります。
DP-700全真模擬試験: https://www.jpshiken.com/DP-700_shiken.html
- 完璧Microsoft DP-700|一番優秀なDP-700日本語版受験参考書試験|試験の準備方法Implementing Data Engineering Solutions Using Microsoft Fabric全真模擬試験 ???? ⇛ www.mogicopyright.com ⇚を開いて⏩ DP-700 ⏪を検索し、試験資料を無料でダウンロードしてくださいDP-700試験勉強過去問
- DP-700 Microsoft試験の準備方法|素晴らしいDP-700日本語版受験参考書試験|更新するImplementing Data Engineering Solutions Using Microsoft Fabric全真模擬試験 ???? 「 www.goshiken.com 」を開いて➽ DP-700 ????を検索し、試験資料を無料でダウンロードしてくださいDP-700学習指導
- DP-700 PDF ???? DP-700最新試験 ???? DP-700試験勉強過去問 ???? ( www.shikenpass.com )は、▶ DP-700 ◀を無料でダウンロードするのに最適なサイトですDP-700模擬練習
- DP-700 Microsoft試験の準備方法|素晴らしいDP-700日本語版受験参考書試験|更新するImplementing Data Engineering Solutions Using Microsoft Fabric全真模擬試験 ???? 今すぐ▛ www.goshiken.com ▟で( DP-700 )を検索して、無料でダウンロードしてくださいDP-700学習教材
- 実際的なMicrosoft DP-700日本語版受験参考書 - 合格スムーズDP-700全真模擬試験 | 最高のDP-700試験参考書 ⚡ ➥ www.copyright.jp ????は、“ DP-700 ”を無料でダウンロードするのに最適なサイトですDP-700対応資料
- 実際的なMicrosoft DP-700日本語版受験参考書 - 合格スムーズDP-700全真模擬試験 | 最高のDP-700試験参考書 ???? 《 www.goshiken.com 》に移動し、➡ DP-700 ️⬅️を検索して無料でダウンロードしてくださいDP-700試験解答
- DP-700試験の準備方法|実際的なDP-700日本語版受験参考書試験|更新するImplementing Data Engineering Solutions Using Microsoft Fabric全真模擬試験 ???? ➡ www.jpcopyright.com ️⬅️にて限定無料の➠ DP-700 ????問題集をダウンロードせよDP-700日本語試験対策
- DP-700日本語解説集 ???? DP-700テスト参考書 ???? DP-700テスト参考書 ???? ⇛ www.goshiken.com ⇚にて限定無料の{ DP-700 }問題集をダウンロードせよDP-700試験解答
- DP-700テスト参考書 ???? DP-700問題トレーリング ???? DP-700学習指導 ???? { www.mogicopyright.com }には無料の「 DP-700 」問題集がありますDP-700問題例
- DP-700 Microsoft試験の準備方法|素晴らしいDP-700日本語版受験参考書試験|更新するImplementing Data Engineering Solutions Using Microsoft Fabric全真模擬試験 ???? ➡ www.goshiken.com ️⬅️に移動し、⏩ DP-700 ⏪を検索して、無料でダウンロード可能な試験資料を探しますDP-700受験対策書
- DP-700 PDF ???? DP-700学習指導 ???? DP-700学習教材 ???? ⏩ www.shikenpass.com ⏪を開き、➥ DP-700 ????を入力して、無料でダウンロードしてくださいDP-700日本語解説集
- www.stes.tyc.edu.tw, www.stes.tyc.edu.tw, kianawwoh814570.slypage.com, www.stes.tyc.edu.tw, aishasthb307951.glifeblog.com, lucyhncu629881.wikifiltraciones.com, jonasdpzw721631.blogspothub.com, lewisaclm755316.bcbloggers.com, animationeasy.com, keithrmie280339.blogsuperapp.com, Disposable vapes
BONUS!!! Jpshiken DP-700ダンプの一部を無料でダウンロード:https://drive.google.com/open?id=1_U42If3OHWuLB628KI0cymEgkxvGUbwq
Report this wiki page